Free Pilot: Pre-Launch Tests for AI Agents
Summary
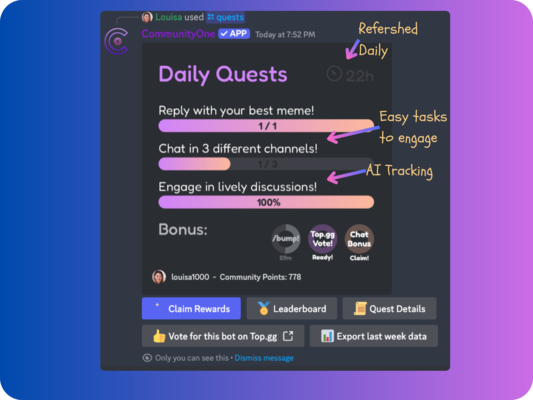
LLM Hub announces a free pilot to test action-taking AI agents before they go live. We simulate realistic workflows to find failures like duplicate refunds, skipped approvals, policy conflicts, wrong escalations, and bad tool calls. Results give a clear decision to ship, patch, block, or require human review, ideal for agencies, SaaS, and support automation teams.